Plus Camp — эвент для техлидов и тимлидов, который устраивают сервисы Яндекса Go и Плюс.
Мне посчастливилось рассказать в подкасте с @Wylsacom про алгоритмы под капотом Яндек Go. (будет доступен в тг)
А еще в дебатле с Женей Смирновым@not_boring_ds, руководителем ML лаборатории в Альфа-Банке почеленджил миф о том, что программистов скоро заменит ИИ.
Хоть и пришлось выступать в каком-то смысле против технологического прогресса, кажется, что удалось подсветить важные ограничения индустрии, которые будут мешать повсеместному внедрению копилотов.
Мы пишем микросервисы. Дальше еще больше микросеврисов, затем еще и еще до того момента как общая картинка перестает умещаться в голове даже самого опытного инженера. А как мы знаем, любую архитектурную проблему можно решить дополнительным слоем абстракции. Появляется идея внедрить DDD.
DDD — не новая методология, о который мы тут не такчастоговорим, но которая призвана, добавив слой абстракции (домены), снизить связанность, возвести заборы (bounded context) и открыть новые возможность масштабирования.
С помощью DDD хочется порешать сразу несколько проблем:
Дальше идут классические подходы к выделению доменов — задача декомпозируется, делегируется командам и те идут дизайнить свое виденье бизнес-сущностей.
В чем ту проблема? Стоит обратиться к классическому закону Конвея:
Современная его трактовка — «Если архитектура системы и архитектура организации противоречат друг другу, победу одерживает архитектура организации»
Команды, исторически образовавшиеся в результате роста компании почти всегда уже поделены по четким зонам ответственности. Если внедрение DDD будет происходить через делегирование нарезание бизнес сущностей командам — вы с немалой вероятностью просто проделаете бюрократическую работу по описыванию зон ответственности, уже закрепленных за существующими командами.
Пример — сервис заказа пиццы. Одна команда отвечает за флоу создания заказа, другая — за его назначения курьеру. Делегировав командам описывать домены, можно получить две бизнес сущности об этом и том же — пользовательский заказ и заказ курьерский. То, что, возможно, одна бизнес сущность — заказ, разъедется по понятиям и не выделится в отдельный домен, а всего лишь подчеркнет текущее разделение между командами.
Редизайн системы нельзя рассматривать только с прикладных технических изменений и идеологий. Важно не только смочь правильно выделить основные сущности бизнеса, но и задуматься об организационной структуре команд. Редизайн системы без реорганизационных изменений с ненулевой вероятностью не взлетит.
The request could not be completed due to a conflict with the current state of the target resource. This code is used in situations where the user might be able to resolve the conflict and resubmit the request.
Часто при дизайне API забывают о 409. Если в описании интерфейса пропущен этот код ошибки, то это очень сильный сигнал к тому, что в API есть гонки.
Упрощенный пример с гонкой: Обновления состояния какого-то объекта
POST update_something?new_value=
Пример почему так делать может быть плохо:
Есть endpoint, который управляет скидками в сервисе: флаг включения скидки и размер самой скидки
POST update_discount?enable=[OPTIONAL]&value=[OPTIONAL]
2 человека, которые видят в веб-интерфейсе одно и то же начальное значение: {enable=false, value=0}.
Один из них хочет изменить {enable=true}, понимания, что новое значение не поменяет поведения, потому что размер скидки установлен 0. Вызывает POST update_discount?enable=true
Другой хочет установить value=30 и только через какое-то время включить саму скидку. Вызывает POST update_discount?value=30
Оба не хотели делать так, чтобы скидка включалась сейчас, однако, последовательность действий привела к обратному.
В хорошем интерфейсе клиент должен понимать, что конкретно он меняет и на что.
Одним из хороших вариантов тут — иметь версию изменяемого объекта. Если версия по каким-то причинам изменилась на бэкенде, то самое время вспомнить про 409 ошибку.
Как может выглядеть интерфейс:
POST update_discount?enable=[OPTIONAL]&value=[OPTIONAL]&version=[REQUIRED]
Клиент явно передает номер версии объекта, который он меняет. Если версия на бэкенде почему-то отличается от той, что присылает клиент, то нужно вернуть 409, чтобы клиент обновил более актуальную версию. В каких-то веб-интерфейсах пользователи часто видят «Версия документа устарела, обновить».
В микросервисной архитектуре встречаются «лавинообразные» падения. Это, например, когда один сервис не вывозит нагрузку и начинает долго обрабатывать запрос, а его клиенты, вместо того, чтобы перестать нагружать сервис, начинают его ретраить, тем самым создавая еще большую нагрузку.
Проблему можно решать несколькими путями. Со стороны клиентов — реализуя классический Circuit Breaker, о котором не так давно был пост.
Со стороны самого запрашиваемого ресурса — это может быть Rate Limiting, или чуть более умный Rate Limiting, про него сегодня и поговорим.
Rate Limiting, как следует из названия — это ограничение количества обрабатываемых операций (единичных запросов, батчей или даже размеров данных за единицу времени). В микросервисах часто предполагается, что если сервису приходит за какое-то временное окно больше N запросов (далее для простоты RPS), то сервис просто «бесплатно» откидывает остальные запросы.
Основная сложность с тем, чтобы выбрать этот самый ограничивающий N.
* Можно провести нагрузочное тестирование и понять количество RPS, больше которых сервис уже не переваривает.
* Еще можно накинуть какой-то процент к пиковым нагрузкам и выбрать это за N.
* Можно даже просто как-то посчитать.
Усложняется все тем, что быстро меняющееся число, которое зависит от характеристик железа, от количества инстансов, на которые распределяется нагрузка, от бизнесс-логики, работающей в конкретный момент времени. Если у вас несколько микросервисов, поддерживать руками актуальный потолок количества запросов весьма затруднительно.
Один из вариантов, это своего рода эвристический механизм Congestion control.
Механизм отслеживает «загруженность» каждого конкретного инстанса каждого конкретного микросервиса. (это может быть CPU, у нас это загруженность «основного процессора задач» нашего веб-фреймворка). Если инстанс самодиагностирует, что он не справляется с нагрузкой (превышен порог задач в очереди), начинает срабатывать лимит RPS. Лимит уменьшается до тех пор, пока инстанс не начнет чувствовать себя лучше. Если инстанс справляется с нагрузкой, лимит постепенно увеличивается. Если долгое время не было перегруза, лимит RPS снимается.
Стоит также обратить внимание, что механизм плохо подходит, если:
— есть требования точного ограничения RPS. Эвристика сильно зависит от того, сколько и в каком режиме используется CPU в текущем контейнере.
— CPU не является ограничивающим ресурсом.
— Не требуется стабильное время отклика. Например, сервис обрабатывает события батчами, батчи могут приходить неравномерно. При этом пиково CPU может быть перегружен, но в среднем ресурсов хватает на обработку потока событий.
— Нагрузка на CPU в процессе обработки запроса продолжается десятки секунд. Механизм предполагает, что ручки отрабатывают быстро, и изменение лимита RPS очень быстро повлияет на загруженность CPU (секунды или доли секунды). Если endpoint отрабатывает длительное время, то обратная связь будет происходить медленно, и сходимость RPS к максимальному RPS не гарантируется.
При разработке новой функциональности мы продвигаем платформенные решения. Это значит, что вместо того, чтобы писать бизнес код, мы инвестируем в разработку платформ, на базе которых можно строить уже непосредственно бизнес решения за очень короткий срок.
Одной из таких платформ является js-pipeline. Система выносит управление бизнес логикой приложения уровень выше. Вместо того, чтобы описывать бизнес логику разработчиком на каком-нибудь C++, мы выносим большую часть бизнес логики в веб-интерфейс. Теперь новую бизнес логику можно описывать на JavaScript прямо из админки.
Это невероятно снижает time to market. Новая бизнес логика вместо долгого деплоя может быть раскатана на пользователей буквально через несколько минут после самой идеи. Все это сильно прибавляет скорости разработки и открывает огромные просторы для бизнеса.
Сегодня мой коллега Ислам приоткрывает завесу над технической частью этого большого проекта.
Паксос — алгоритм принятия решений в распределённых системах, лежащий в основе многих современных инструментов — Consul, Zookeeper, etcd и других.
Зачастую при работе распределенной системы возникает необходимость принимать общие решения, например, на каком из инстансов запустить задачу, которая должна быть выполнена один раз.
Задача решается просто, когда есть арбитр — главный в принятии решений. Проблема в том, что такой арбитр становится узким местом и при его отказе происходит сбой в работе.
Устойчивая к неполадкам система должна состоять из равноправных участников, способных договариваться между собой — достигать консенсуса.
Алгоритм Паксос (Paxos), придуманный и доказанный Лесли Лампортом, говорит нам о том, как этого консенсуса можно достичь. Критерием достижения является согласие с предложением более половины участников.
Алгоритм состоит из двух этапов:
Подготовительный этап:
Предлагающий рассылает анонс, что он планирует сделать предложение n (в момент времени n).
Принимающие получившие анонс посылают в ответ обещание не принимать никаких предложений с номерами меньшими n (до момента n), а также последнее принятое предложение (номер и значение) или не отвечают вовсе, если номер последнего принятого принимающим предложения превосходит n.
Предложение:
Предлагающий, получив ответы от большинства принимающих, выбирает в качестве значения предложения v значение из ответа с максимальным номером предложения и рассылает предложение (n, v).
Принимающий, получив предложение (n, v), обязан принять его если он, конечно, не пообещал другому предлагающему не принимать предложений с номерами меньшими n*, где n* > n.
Интересные моменты: — Консенсуса можно вовсе не достигнуть из-за большого количества предлагающих. Для решения этой проблемы можно ввести случайные задержки. — Повреждение данных на доле узлов может расколоть вашу систему на несколько частей.
В микросервисной ахриктектуре бывают зависимости, которые накладывают определенные ограничения на используемые сервисы.
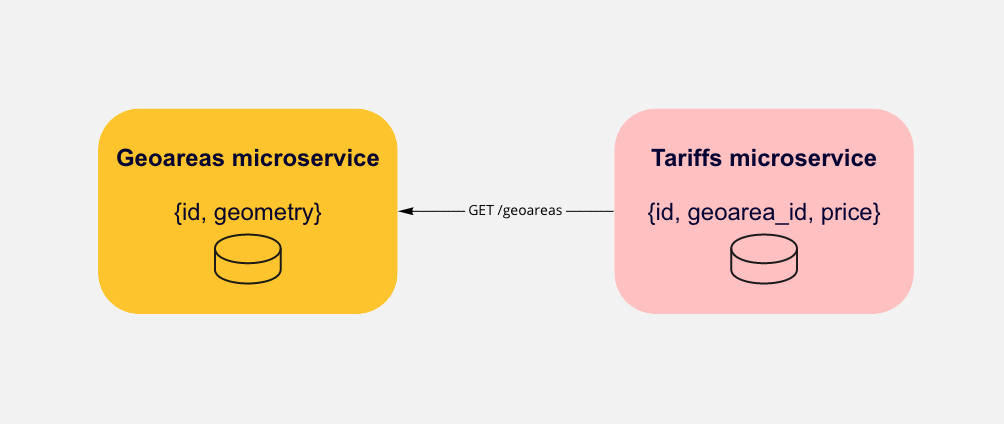
Для примера, рассмотрим сервис аренды машин, где используется принцип database per service:
Микросервис geoareas владеет данными о разных географических полигонах — городах, районах: {id, geometry}
Микросервис tariffs в свою очередь распоряжается данными о стоимости аренды: {id, geoarea_id, price_per_minute}. Есть зависимость от сервиса geoareas.
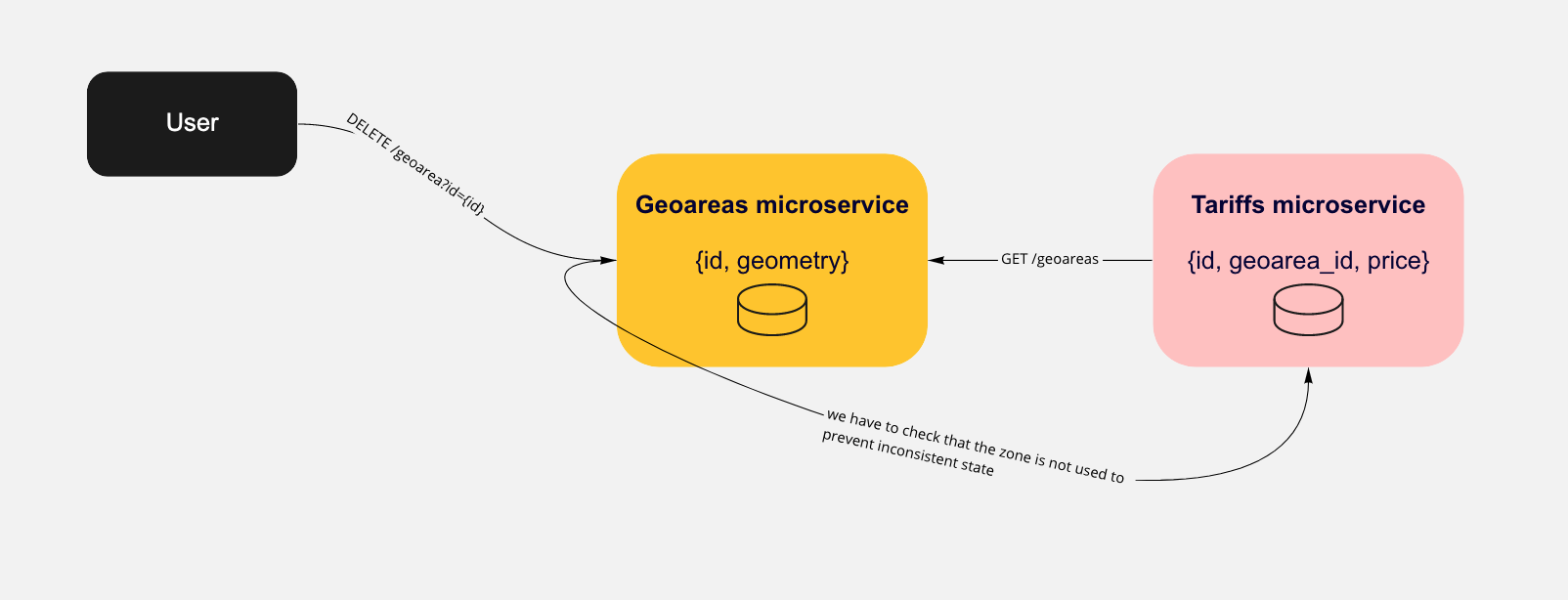
В какой-то момент нам понадобилось удалить объект из микросервиса geoareas — вызвать endpoint:
DELETE /geoarea?id={id}.
Это может повлечь ряд проблем вплоть до недоступности микросервиса, т.к. у нас останутся тарифы, указывающие на удаленную геозону.
Появляется неприятная зависимость: чтобы удалить геозону из geoareas нужно в момент удаления сделать запрос в tariffs, чтобы проверить — не зависит ли от нее какой тариф.
Появляется опасная связанность — при таком подходе geoareas в будущем будет отправлять запросы во все микросервисы, где используются геозоны.
В базах данных, кстати, есть автоматический контроль целостности с помощью внешних ключей.
У нас же распределенная микросервисная архитектура и есть несколько вариантов решения:
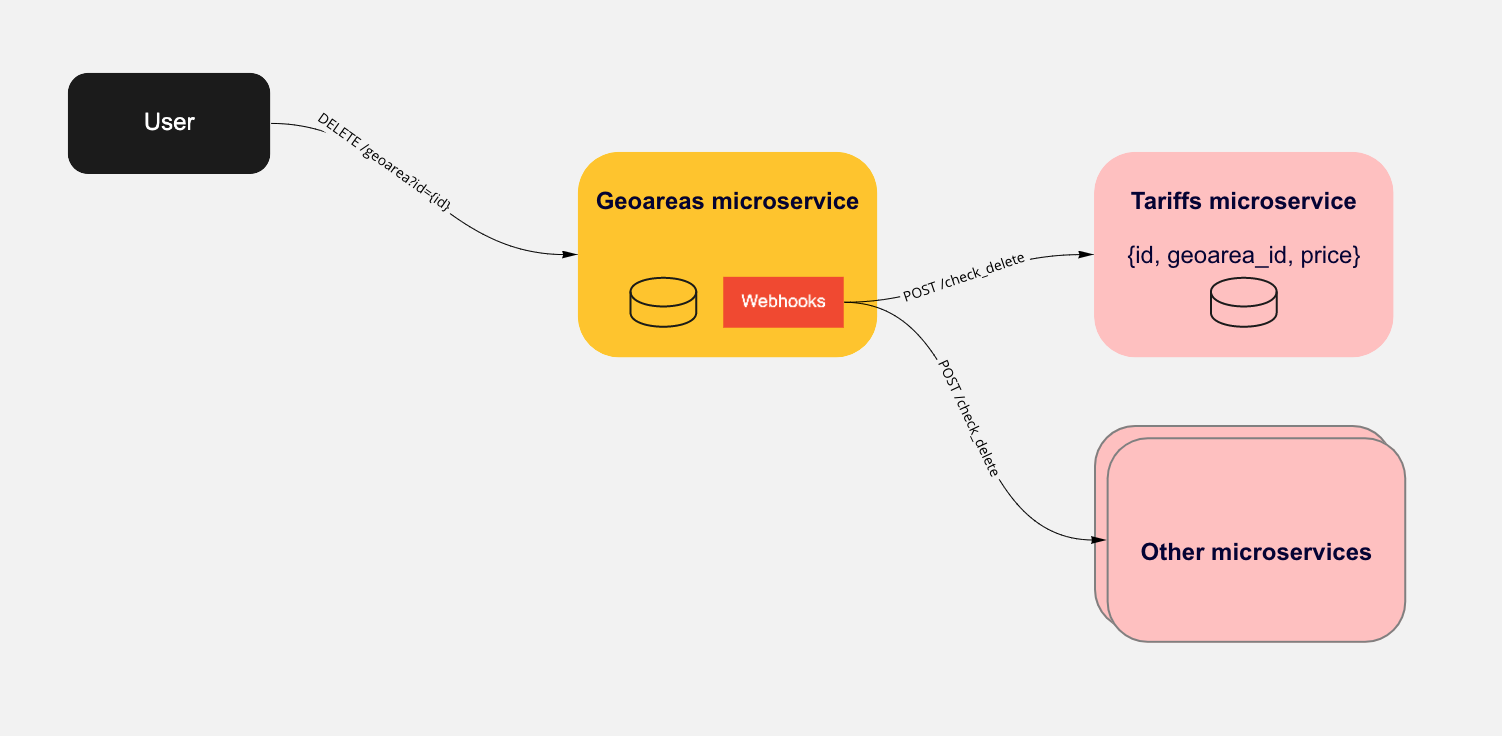
1. Webhooks
Вариант подразумевает создание в микросервисе, от которого будут зависеть другие микросервисы унифицированного механизма веб-хуков.
Микросервис будет исполнять эти хуки перед тем, как изменить объект. Если хоть один хуков завершился неудачей, то действие над объектом невозможно.
Примером такого веб-хука может быть запрос в сторонний микросервис с предопределенным API. Для нашего примера веб-хук в микросервисе geoareas выглядел бы следуюшим образом:
В микросервисе tariffs, соответственно, нужно реализовать endpoint /check_delete для проверки того, что зону можно удалить и микросервис tariffs «не против».
Унифицированность таких хуков позволяет легко конфигурировать их на лету. При появлении нового микросервиса, который использует geoareas добавлять в список хуков новую проверку.
Таким образом, geoareas поддерживает механизм унифицированных веб-хуков, но ничего не знает про то, что за логика внутри этих хуков.
2. Reference Counting
В этом варианте мы будем следить за тем, кто использует геозоны.
Расширяем API нашего микросервиса geoareas следующими endpoints:
POST /hold?geoarea_id={id}&holder={holder}
POST /release?geoarea_id={id}&holder={holder}
Таким образом, если хотим создать новый тариф в зоне, то перед этим нужно эту зону заблокировать в сервисе geoareas, например:
POST /hold?geoarea_id=moscow&holder=tariffs_tariffmoscow1
Рядом с геозонами в микросервисе geoareas будем хранить список тех, кто «держит» эти геозоны.
При попытке удаления геозоны проверяем список держателей и не даем удалять, если список не пуст.
Если тариф, держащий геозону, удаляется, то после удаления нужно отпустить блокировку, например:
POST /release?geoarea_id=moscow&holder=tariffs_tariffmoscow1